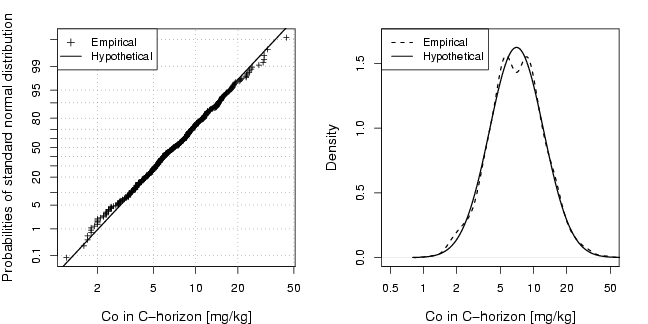
library(StatDA)
data(chorizon)
Co=chorizon[,"Co"]
n=length(Co)
pdf("fig-9-1.pdf",width=9,height=4.5)
par(mfrow=c(1,2),mar=c(4,4,2,2))
qpplot.das(log10(Co),qdist=qnorm,xlab="Co in C-horizon [mg/kg]", lwd=1.5,
ylab="Probabilities of standard normal distribution", pch=3,cex=0.7, logx=TRUE,
logfinetick=c(2,5,10),logfinelab=c(2,5,10),cex.lab=1.2)
legend("topleft",legend=c("Empirical","Hypothetical"),lty=c(NA,1),pch=c(3,NA),cex=0.95,bg="white",
lwd=c(NA,1.5))
plot(d <- density(log10(Co)),main="",xlab="Co in C-horizon [mg/kg]",xaxt="n",cex.lab=1.2,lty=2,
xlim=c(log10(0.5),log10(50)),ylim=c(0,1.7),lwd=1.5)
axis(1,at=log10(a<-sort(c((10^(-50:50))%*%t(c(2,5,10))))),labels=a)
lines(d$x,dnorm(d$x,mean(log10(Co)),sd(log10(Co))),lty=1,lwd=1.5)
legend("topleft",legend=c("Empirical","Hypothetical"),lty=c(2,1),lwd=c(1.5,1.5),cex=0.95)
dev.off()